










What We Learned from Turning Bug Hunting into a Game at Blits.ai

In the first week of January we did something a bit unusual at Blits.ai:
We turned bug hunting into a game.
Instead of treating quality as a background activity, we made it explicit, visible, and competitive. Non‑technical colleagues became Hunters. Engineers became Fixers. I played the Judge. And behind the scenes, a Nuxt.js app pulled live data from Azure DevOps to keep score on a real‑time leaderboard.
This post is a recap of what we built, what actually happened in that week, and what we learned.
How the Bug Hunt Game worked
We defined three roles:
- Hunters (non‑technical): responsible for finding and documenting bugs in enough detail that someone else could reproduce and fix them.
- Fixers (technical): responsible for taking bugs from “this is broken” to “this is fixed and tested”.
- Judge (me): responsible for enforcing the rules, validating quality, and occasionally stealing points when the process wasn’t followed.
Everything was tracked in Azure DevOps. If a bug had the Bug Hunt Game 2026 flag, it became part of the game. The Nuxt leaderboard app pulled that data through the Azure DevOps API and calculated points in real time:
- +1 point for each valid bug report (Hunter).
- +1 point if the original Hunter verified the fix themselves.
- +1 point for adding a help center article or instructions.
- +1 point for fixing a bug (Fixer).
- +2 points for adding unit tests, e2e tests or recurring validation to prevent regressions.
And because every game needs some chaos, the Judge had the power to invalidate, bonus, or steal points when the process wasn’t followed.
The actual numbers from week one
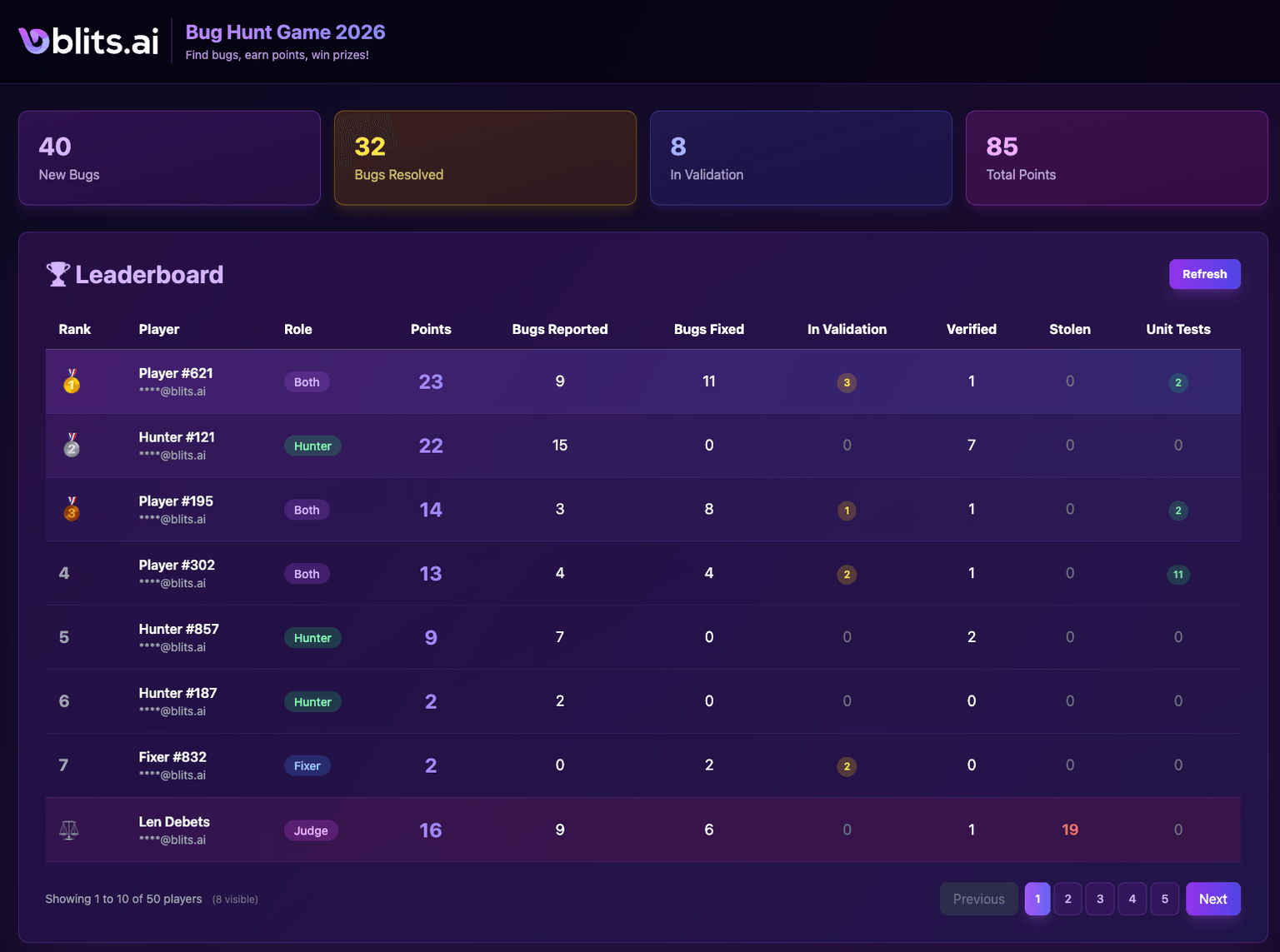
By the end of the first week of January, the scoreboard looked like this:
- 49 bugs identified and tracked with the game flag.
- 32 bugs resolved and verified as fixed.
- 85 total points earned across 7 active players.
- 15 new unit tests added to our codebase.
- 8 bugs still in validation (fixed but waiting for final confirmation).
On paper, those are just numbers. In practice they meant:
- We surfaced bugs that would normally sit in someone’s notes or chat history.
- We pulled non‑technical colleagues directly into the quality process.
- We turned “please add tests” into a concrete, rewarded action.
Instead of a vague “we should improve quality this quarter”, we had a visible, measurable week where quality work was the only thing that mattered.
Who ended up on top (and why)
The top three players on the leaderboard were:
- 🥇 Player 1, 23 points (9 bugs reported, 11 fixed, 2 unit tests).
- 🥈 Player 2, 22 points (15 bugs reported, clear top Hunter).
- 🥉 Player 3, 14 points (3 bugs reported, 8 fixed, 2 unit tests).
A few interesting patterns:
- The people who reported bugs and also fixed them tended to climb fastest. The “Both” role (Hunter + Fixer) was naturally rewarded.
- Pure Hunters still had a strong impact. Yuri didn’t fix bugs, but his reports unlocked a lot of downstream work.
- Unit tests quietly made a difference. They are “only” +2 points, but they often decided the difference in tight rankings.
I, as the Judge, was of course on the leaderboard—but always anchored to the bottom and excluded from winning. My role was to keep the game fair, not to win it.
What changed in our behaviour
The most important outcome was not the points, it was the behaviour they created.
1. Better bug reports from non‑technical teammates
Hunters quickly learned that vague “it doesn’t work” tickets didn’t score. To earn points, they needed:
- A clear description.
- Steps to reproduce.
- Environment or device information.
- Evidence like screenshots or video.
After a few rounds of feedback, the average bug report quality went up dramatically. Fixers spent less time guessing and more time actually fixing.
2. A healthier pressure to add tests
Developers already know they should add tests. The game turned that into a visible incentive:
- Add a test → get rewarded.
- Skip tests → you can still fix the bug, but you leave points on the table.
By the end of the week we had 15 new tests in the codebase, tied to real bugs that had caused real problems. That’s much more valuable than abstract “test coverage” goals.
3. Shared language between business and engineering
Because everything lived on a single leaderboard, non‑technical and technical people talked about the same objects:
- “This bug is in validation.”
- “You’ll get the verification point when you confirm it’s fixed.”
- “I’ve added a test, can you double‑check the behaviour and close it?”
Instead of “devs versus business”, the game pushed everyone into a shared mental model of Hunters, Fixers, and a Judge working through the same backlog.
Why we built a custom app instead of a spreadsheet
We could have run this in a spreadsheet. But we wanted the game to feel real, not administrative.
So we built:
- A Nuxt.js leaderboard app styled like a real game dashboard.
- Server‑side endpoints to pull bugs and player stats directly from Azure DevOps.
- Logic to handle edge cases: judges stealing points, verification rules, states like “Tested, Ready for Prod”, and date windows for valid bugs.
- A bug list view showing who reported what, who is working on it, and which tags (tests, articles) are attached.
The end result was a live scoreboard that people could refresh during the week and watch themselves move up or down. That matters. It turns abstract work into visible progress.
What we’ll change for the next round
The first edition worked, but there are things we want to adjust:
- Clearer seasons: Fixers could still earn points for older bugs fixed during the week. Next time we may limit both reporting and fixing to a stricter time window.
- More structured rewards: In this round the prize structure was simple. Future games could have categories like “Best Bug Report”, “Most Valuable Test”, or “Most Impactful Fix”.
- Automatic recognition: Right now the game is internal. We’d like to surface anonymized stats in more places, like internal dashboards or company‑wide updates.
The most important learning: once you make quality visible and fun, people naturally lean into it.
Final thoughts
The Bug Hunt Game started as an experiment, but it did three things very well: it pulled non‑technical people into the quality loop in a structured way, it rewarded testing and documentation instead of just closing tickets, and it gave us concrete numbers to talk about, bugs found, bugs fixed, tests added, players involved.
At Blits we spend most of our time helping enterprises build production‑grade AI and conversational systems. This little internal game reminded us that sometimes the most powerful improvements in quality don’t come from new tools at all, but from changing how people see the work.
And if you can turn that work into a game with a leaderboard, medals, and a slightly evil Judge?
Even better.
Stay Updated
Get the latest insights on conversational AI, enterprise automation, and customer experience delivered to your inbox
No spam, unsubscribe at any time